Transform, Optimize and Deploy
Transforming the solution data model to a concrete physical model is a pleasant task that demands both familiarity with:
1) business requirements (user stories) and
2) competency in physical modeling (for the target of your choice).
At this point in the process, you’ll likely already be quite familiar with the business requirements at hand; they’ve been relevant in every step. We cannot help you with the second requirement. There exist plenty of other good sources, closer to the vendors, which can help you with that.
Here we will examine how visual representations of graph solution data models can help us determine, which transformations we will need.
We’ll also get useful mapping information on the business level, if we visualize the selected transformations.
A good example of the synergy between the three modeling levels is the matter of hierarchies. These exist on the business level, and can be seen in concept maps and in solution data models. However, they tend to disappear (because of denormalization) at the physical level.
The type of physical model you end up using in a given solution can have some effects on requirements for detailed preservation of history (e.g. Type 2 level of versioning as it appears in data warehouses and other places). If you have those kinds of requirements, please make sure your choice of physical data store is compatible with them.
Also remember that most of these products do not “join” in the SQL sense.
Document and graph databases do offer good possibilities for relating things; otherwise, you will have to rely on applications to perform joins. This will influence your design; you should try to cater to frequent query patterns in the design of the physical data model. Identifying these is what the user stories are for. Go back to your concept maps and consult the business level relationships/dependencies before you get too deep into the physical design.
1) business requirements (user stories) and
2) competency in physical modeling (for the target of your choice).
At this point in the process, you’ll likely already be quite familiar with the business requirements at hand; they’ve been relevant in every step. We cannot help you with the second requirement. There exist plenty of other good sources, closer to the vendors, which can help you with that.
Here we will examine how visual representations of graph solution data models can help us determine, which transformations we will need.
We’ll also get useful mapping information on the business level, if we visualize the selected transformations.
A good example of the synergy between the three modeling levels is the matter of hierarchies. These exist on the business level, and can be seen in concept maps and in solution data models. However, they tend to disappear (because of denormalization) at the physical level.
The type of physical model you end up using in a given solution can have some effects on requirements for detailed preservation of history (e.g. Type 2 level of versioning as it appears in data warehouses and other places). If you have those kinds of requirements, please make sure your choice of physical data store is compatible with them.
Also remember that most of these products do not “join” in the SQL sense.
Document and graph databases do offer good possibilities for relating things; otherwise, you will have to rely on applications to perform joins. This will influence your design; you should try to cater to frequent query patterns in the design of the physical data model. Identifying these is what the user stories are for. Go back to your concept maps and consult the business level relationships/dependencies before you get too deep into the physical design.
Hierachical Aggregation Schemes
Key-value stores, for example, differ in their physical model. Key-wise, they contain either just one key or multiple key fields (implying a hierarchical structure of the data).
Column-wise, they include either just one value column (which may become very large) or multiple value columns.
These are called many names: “column family databases,” “big tables,” “wide tables,” or “long row designs”. Essentially, the column-wise physical models are applications of the repeating group paradigm, such that every row contains column(s) for each occurrence of the repeating data. Consider, for example, the multiple phone number example above.
Denormalization will have to cater to that. For example, sketching an aggregate structure (in the domain-driven design paradigm) could look like this:
Column-wise, they include either just one value column (which may become very large) or multiple value columns.
These are called many names: “column family databases,” “big tables,” “wide tables,” or “long row designs”. Essentially, the column-wise physical models are applications of the repeating group paradigm, such that every row contains column(s) for each occurrence of the repeating data. Consider, for example, the multiple phone number example above.
Denormalization will have to cater to that. For example, sketching an aggregate structure (in the domain-driven design paradigm) could look like this:
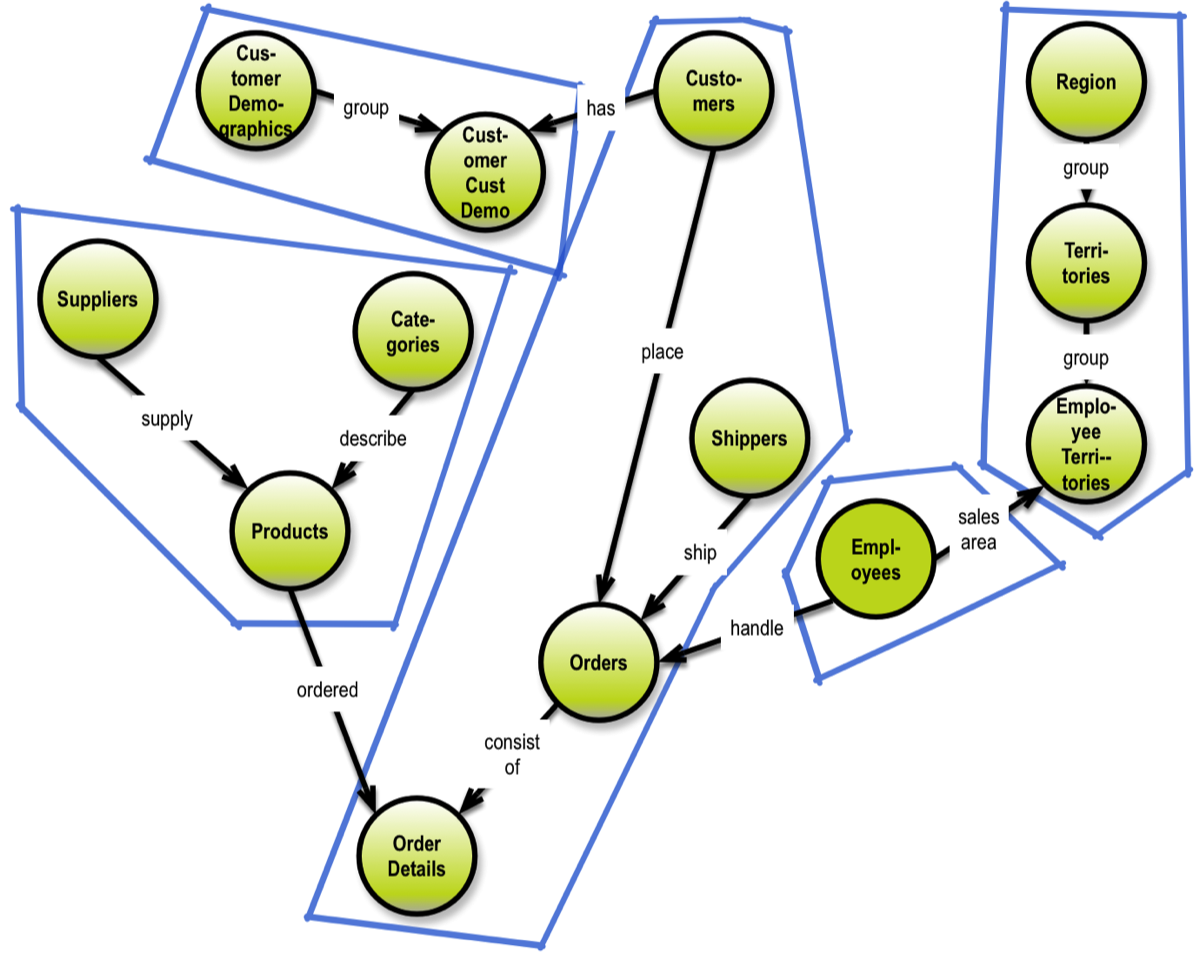
If you use a single-valued key-value approach, you could introduce an extra “navigation field” denoting the type of content in the data column. That pattern could extend over multiple levels down a hierarchy:
“Person:Employee:Name:Thomas”.
Aggregates essentially deliver hierarchies for each relevant sub-tree of the solution data model. Note that aggregation might imply denormalization as well; the result will always have redundant data. Consider this when designing your model. If the redundant data is processed at different stages of a lifecycle, it might work well.
The considerations for delivering data models for document stores are very similar to those for delivering aggregated data models, as described in the preceding section. The term “collections“ is often used to refer to a collection of data that goes into a separate document.
Many document stores offer flexibility of choice between embedding or referencing. Referencing allows you to avoid redundancy, but at the cost of having to retrieve many documents. In fact, some products go to great lengths to deliver graph-style capabilities, both in the semantic “RDF triplets” style and in the
general “directed graph” style.
In this manner, what your physical design will likely end up with is a set of related collections that reference each other; these could be arranged in many-to-many relationships, if need be.
Many document stores offer flexibility of choice between embedding or referencing. Referencing allows you to avoid redundancy, but at the cost of having to retrieve many documents. In fact, some products go to great lengths to deliver graph-style capabilities, both in the semantic “RDF triplets” style and in the
general “directed graph” style.
In this manner, what your physical design will likely end up with is a set of related collections that reference each other; these could be arranged in many-to-many relationships, if need be.
Property Graph Databases
If you follow the suggestions of the Graph Data Modeling book, your solution data model is already a property graph. This, of course, makes moving it to a propertygraph platform very easy.
Look at the examples in section 4.1, and later in chapter 5. If you want more “graph-ish” modeling tips, you can look into this (free) book from Neo4j: http://bit.ly/29VFvPZ.
Property graphs are quite rich in their expressiveness, and allow for example properties on relationships, which should be used for describing some important feature(s) of the relationship like strength, weight, proportion, or quality.
Relationships are essentially joins between nodes, with one big difference. A relationship called “produces” may well point to different types of business objects, like “part” and “waste.” This is both a strength and a weakness. It’s positive because it reflects the way people think about reality. It’s negative because people might get confused, if the semantics are unclear. These considerations are very good reasons to define a solution data model, even if your physical data model is going to be based on a “flexible” or even non-existing schema.
Much of the flexibility of the graph model can be used to handle specialization on the fly. That is fine in most cases, but specializations hang off more precisely defined structures. And the precisely defined structures is what you have in your solution data model.
In graph databases you can use ordered, linked lists.
Here is an example of establishing purchasing history for customers by way of using a “next order” relationship:
Look at the examples in section 4.1, and later in chapter 5. If you want more “graph-ish” modeling tips, you can look into this (free) book from Neo4j: http://bit.ly/29VFvPZ.
Property graphs are quite rich in their expressiveness, and allow for example properties on relationships, which should be used for describing some important feature(s) of the relationship like strength, weight, proportion, or quality.
Relationships are essentially joins between nodes, with one big difference. A relationship called “produces” may well point to different types of business objects, like “part” and “waste.” This is both a strength and a weakness. It’s positive because it reflects the way people think about reality. It’s negative because people might get confused, if the semantics are unclear. These considerations are very good reasons to define a solution data model, even if your physical data model is going to be based on a “flexible” or even non-existing schema.
Much of the flexibility of the graph model can be used to handle specialization on the fly. That is fine in most cases, but specializations hang off more precisely defined structures. And the precisely defined structures is what you have in your solution data model.
In graph databases you can use ordered, linked lists.
Here is an example of establishing purchasing history for customers by way of using a “next order” relationship:
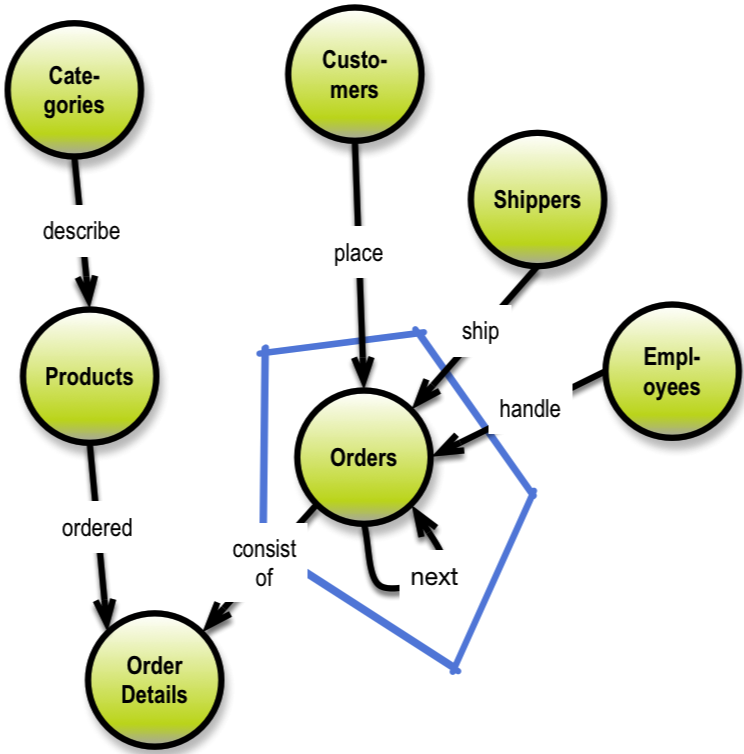
Prior links could also be useful in situations like this. “Prior orders” could be useful in some applications.
In this manner time-series data can be handled elegantly in graphical representations using next / prior linking.
If you find yourself working extensively with these applications that work well with graph databases, you can bite the bullet and go “all graphs.” Alternatively, you can architect a solution that is part-graph and part-something else (SQL, for example).
In this manner time-series data can be handled elegantly in graphical representations using next / prior linking.
If you find yourself working extensively with these applications that work well with graph databases, you can bite the bullet and go “all graphs.” Alternatively, you can architect a solution that is part-graph and part-something else (SQL, for example).
Differences between Relational and Graph databases like Neo4j
Modeling physical graph data models in e.g. Neo4j does have some design issues to deal with, for example:
- What goes into a Node, a Relationship and a Property? Sometimes a property, for example, is better modeled as a node and vice versa
- An upfront schema not absolutely necessary, but knowing what you work with, is …
- Incremental extensions of the model
- Early testing on realistic data (but possibly not too many…)
- Frequently designed for specific queries / analytics (user stories)
- Labels are fast, properties can be indexed, but…
- Named relationships!
- Multiple labels, but not too many
- Join tables in relational become relationships (even M:M, but …)
- Lists (like a repeating group in relational)
SQL as Target Model
Transforming a solution data model from a property graph format into a relational data model using SQL tables is straightforward. Each node becomes a table, and the identity fields and the relationships control the primary / foreign key structures.
In the little employee-department data model from the seventies (Peter Chen), the transformations look like this. First, the solution data model:
In the little employee-department data model from the seventies (Peter Chen), the transformations look like this. First, the solution data model:
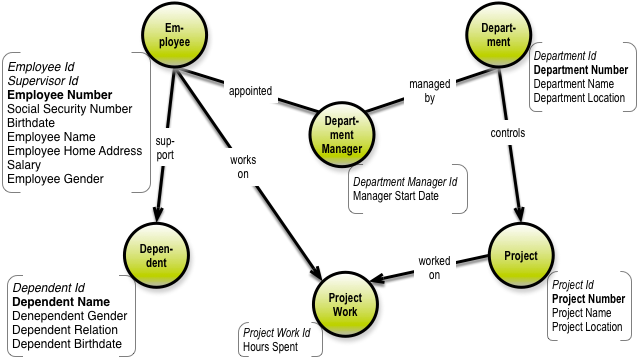
What remains to be done is defining the keys etc. Each table has unique business key (Employee number, for example), a unique physical, surrogate key (Employee ID, for example) and potentially one or more foreign keys (pointing to surrogate keys in other tables).
The Graph Data Modeling book has more information and more examples of doing the transformations from the solution level to the physical levels. And also on how to do a solution data model in the first place, of course!
You may follow the sequence or explore the site as you wish:
Based on the ideas on this page there is now a way of recycling existing metadata (XML, UML, ERD etc.) into graph data models. This books contains all you need, incl. 40+ scripts for auto-generation of data models:

For more information: Contact the author at the email indicated at the bottom of the page.
You could also take a look at the book about Graph Data Modeling:
