Evolution of Database
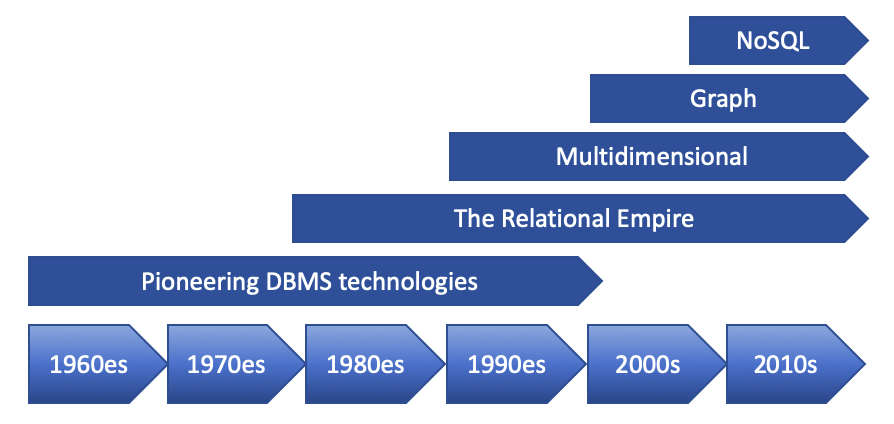
The database evolution happened in five “waves”:
- The first wave consisted of network, hierarchical, inverted list, and (in the 1990’s) object-oriented DBMSs; it took place from roughly 1960 to 1999.
- The relational wave introduced all of the SQL products (and a few non-SQL) around 1990 and began to lose users around 2008.
- The decision support wave introduced Online Analytical Processing (OLAP) and specialized DBMSs around 1990, and is still in full force today.
- The graph wave began with The Semantic Web stack from the Worldwide Web Consortium in 1999, with property graphs appearing around 2008
- The NoSQL wave includes big data and much more; it began in 2008.
Evolution of Data Modeling
- 1973: Charles Bachman with “The Programmer as Navigator”
- 1981: E. F. (Ted) Codd with “Relational Database: A Practical Foundation for Productivity”
- 2001: Ole-Johan Dahl and Kristen Nygaard for ideas fundamental to the emergence of object-oriented programming
- 2014: Michael Stonebraker with “The Land Sharkx are on the Squawk Box.”
Let us look back at the history of database in a slightly different manner.
There was a lot of ground to cover for the pioneers of Database Management Systems, and they have done a fine job. The first twenty to twenty-five years introduced and fine-tuned important technological fundamentals.

- Complexity of data modeling (“normalization …”) and of SQL
- Performance.
- Recently a mathematical incompleteness claim has come from a company called Algebraix Data. They claim that the relational model as defined by Dr. Codd is not really a consistent model since it cannot support sets of sets.
- Other criticisms accused SQL of not being a “well-formed” and complete (in the mathematical sense) computer language.
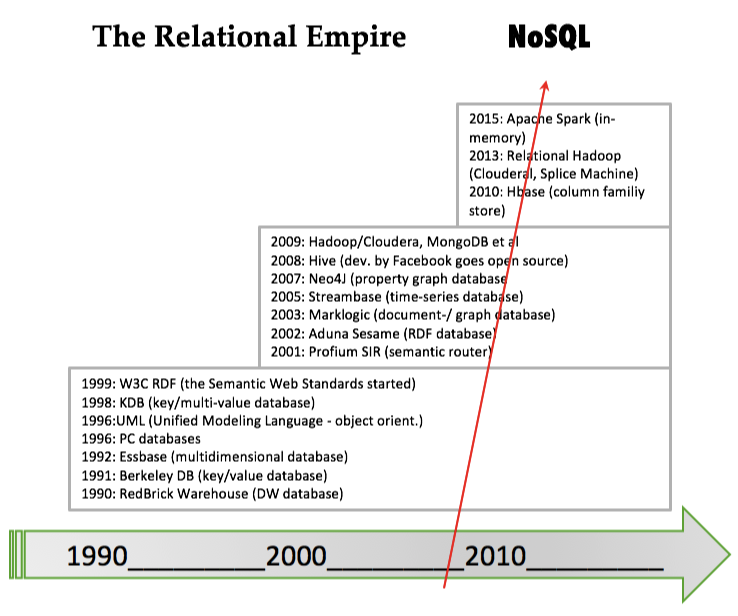
1990 is the start of the “relational empire” because by then, the costbased query optimizers had reached sufficient sophistication to allow the RDBMS products to take over most of the database processing across most industries.
Not much new relational technology was published through the 1990’s and early 2000’s. In fact, entrepreneurs (in California, mostly) were busy developing alternatives to the relational approach. Quite a few of the new companies and products were focused on specialized niches such as documents, graphs, semantics, and high-volume applications.
Today, vendors unite under the NoSQL / Big Data brand. In one white paper, a non-relational vendor (MarkLogic) very succinctly complained of relational models: “Relational database vendors are still offering users a 1990’s-era product using code written in the 1980’s, designed to solve the data problems of the 1970’s, with an idea that came around in the 1960’s.”
NoSQL
2008 was indeed a turning point. This can also be seen in the report of the very influential summit of database researchers, which have met in 1989, 1990, 1995, 1996, 1998, 2003, 2008 and 2013. In 2008, big data was the number one factor for a “sense of change” (The Claremont Report on Database Research, downloaded from http://bit.ly/2abBidh on 2016-02-27.)
So, where do we go now? How to balance the “what” and the “how” in light of NoSQL and all of the new technologies?
Well, the modern development platforms use schema-free or semi-structured approaches (also under the umbrella of NoSQL). “Model as you go” is a common theme, while data modelers and data governors are seen as relics from the past. Surveys (e.g. Insights into Modeling NoSQL, A Dataversity Report 2015, by Dr. Vladimir Bacvanski and Charles Roe) confirm this. Modeling for NoSQL is very often performed by the developer on the fly.
Graph - Semantic vs. Property Graph
Around 2008 both Apache Tinkerpop and Neo4j's Cypher language appeared as being the first property graph database implementations.
Originally graph was considered part of NoSQL, but with the heavy focus the area has today, it deserves to be named a wave in its' own right.
This website (graphdatamodeling.com) is dedicated to graph technologies, mostly of the labeled property graph kind, but with a keen eye on the semantic graph capabilities as well.
The question that this site tries to answer is: How then can we choose what to carry over from the data modeling legacy, if anything at all? The answer is found in the Graph Data Modeling Book.
The Importance of Semantics
Evolution of Graph Data Models
1969
Conference on Data Systems Languages Database Model, network databases.
1970
A Relational Model of Data for Large Shared Data Banks, E. F. Codd, leading to Functional Dependencies in relational theory and later in the SQL standard (cf. ISO/IEC 9075-2:2016 - Information technology — Database languages — SQL — Part 2: Foundation).
1976
John F. Sowa’s work on conceptual graphs as visualizations of First order logic. This led to the ISO standard on Common Logic (ISO/IEC 24707:2007 - Information technology — Common Logic (CL): a framework for a family of logic-based languages").
1976
Fact statements (conceptual modelling and object-role modeling), G. M. Nijssen and E. Falkenberg.
1976
Entity-Attribute-Relationship Model, Peter Chen, original visualizations similar to graphs.
1999
Triples (RDF, semantics, ontologies etc.) in the W3C web data standards.
2007
Relationships / edges (various kinds of property graphs from multiple database vendors).


