Legacy Data Models in UML etc. can be Recycled into Graph Data Models
Why waste good legacy data models just because you go to graph database? Literally legions of data modelers have spent tons of hours and days on producing (mostly) rather good representations of a business context. AKA data models.
There 70+ ERD-supporting data modeling tools and a list of 50+ UML tools. This translates to hundreds of thousands of good, reusable data models! Why waste such a large resource of business metadata?
There 70+ ERD-supporting data modeling tools and a list of 50+ UML tools. This translates to hundreds of thousands of good, reusable data models! Why waste such a large resource of business metadata?
New edition: Now also supports FileMaker(R) data models!
Much similar to data science we need to be able to (in "Metadata Science") to read, transform, scope / reduce / enhance and adapt to modern database technologies. Not least graph databases, if you ask me.
This book contains all you need to do this for the legacy data models - scripts, models and flows.

Recycle, Reuse and Reduce also apply to data models!
Why waste time remodeling the same data again, because you change platform? Explore how to auto-generate graph data models (for Neo4j) from legacy data models in UML, XML, ERD, concept maps and other formats. And it includes a design of a metadata repository giving you full scale control.
There are 7 different contexts supported so far:
Why waste time remodeling the same data again, because you change platform? Explore how to auto-generate graph data models (for Neo4j) from legacy data models in UML, XML, ERD, concept maps and other formats. And it includes a design of a metadata repository giving you full scale control.
There are 7 different contexts supported so far:
- A Concept Map (CmapTools, CXL/XML format)
- An OASIS OData CSDL Definition XML-file
- A XML Schema
- A StarUML Class Model in XPD-format
- An Eclipse PapyrusUML Class Model in a XMI-file
- A UML Class Model in SparxSystems’ EA Tool in a XMI-file
- A Data Model from FileMaker in a database report in XML format
Everything you need (incl. scripts etc.) is available as an eBook! If you are interested, send an email to info @ graphdatamodeling.com.
Bonus Content
The book also explains how to build a simple graph-based metadata repository for:
Cypher-scripts for repository handling are indeed also part of the book (under a MIT license)..
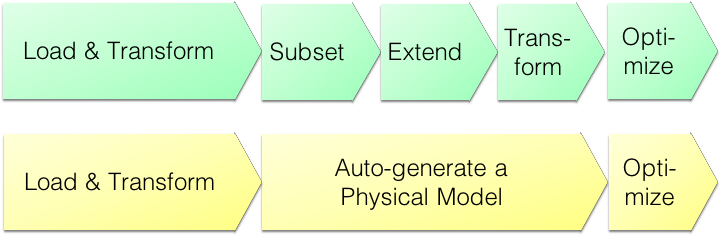
We suggest a choice of two approaches:
The book also explains how to build a simple graph-based metadata repository for:
- Business level concept models
- Solution level logical data models, and
- Physical models.
Cypher-scripts for repository handling are indeed also part of the book (under a MIT license)..
We suggest a choice of two approaches:
- Fast Track Data Models (agile)
- Super Data Models (crafted, using the repository):
Missing a data modeling tool on the list? Suggestions of other formats to be supported can be sent to @VizDataModeler (info at graphdatamodeling dot com).
For more information: Contact the author at the email indicated at the bottom of the page.
Want to know more about graph data modeling in general? Read the book:

